

[AWS EKS] ลองใช้ Cluster autoscaler สำหรับ Scale K8s
![[AWS EKS] ลองใช้ Cluster autoscaler สำหรับ Scale K8s](https://thanapon.info/wp-content/uploads/2023/11/k8s-cluster-autoscaler.png)
ก่อนอื่นต้องเกริ่นก่อนครับ พอดีตอนนี้ในทีมได้มีโอกาสใช้ K8s ในการ deploy service ขึ้นไปใช้งานภายในบริษัท ซึ่งปกติตอนที่เรา Provision cluster ขึ้นมานั้น K8s Cluster พวกนี้ก็ไม่ได้เพิ่ม tools สำหรับการทำ Auto scaling เข้ามาให้ด้วย จากเดิมปกติถ้าเราทำการ config EKS นั้นมันก็จะมีให้สร้าง Node group อะไรต่างๆบลาๆๆ โดยที่ภายใน Node group ที่สร้างนั้นมันก็มีให้ระบุ Desired, Minimum และ Maximum เพื่อให้ Node group แต่ละตัวมันสามารถ Scale ได้ แต่วิธีการ Scale เราจะต้องไปปรับเองแบบ Manual นะสิ! แบบนี้ก็เกิดปัญหาเลยสิถ้าจะต้องมีคนมาเฝ้าดูการทำงานของ Container ทั้งวันทั้งคืน “ทีนี้ก็ลำบาก ก็ว้าวุ่นกันทีเดียว”
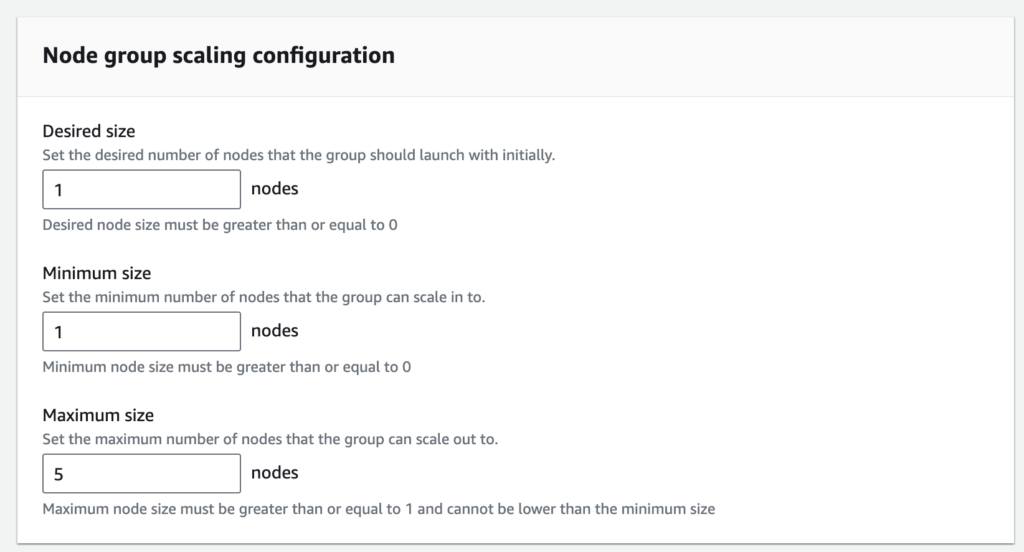
ซึ่งวิธีการ Scale แบบนี้ในฝั่งของ Kubernetes จะเรียกว่าการ Scale แบบ Vertical scaling ซึ่งก็คือการเพิ่ม CPU/Memory เข้าไปใน K8s Cluster เพื่อให้ Cluster นั้นสามารถรัน pod ได้เยอะๆ
จากปัญหาข้างต้น AWS เขาก็ได้แนะนำวิธีการ Auto scaling node ที่รันอยู่ใน EKS Cluster ด้วยกัน 2 วิธี
- Karpenter คือ Opensource tools ตัวหนึ่งที่เราจะต้องทำการ setup ลงไปใน cluster ของเราเพื่อให้มัน Watching, Evaluating, Provisioning และ Removing ตัว worker node โดยที่มันก็ถูกสร้างเพื่อให้ใช้งานกับ AWS เท่านั้น
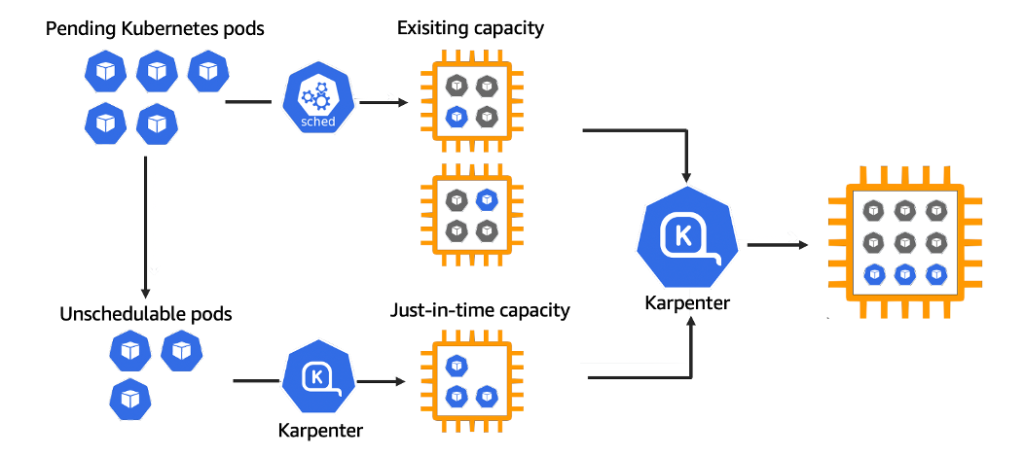
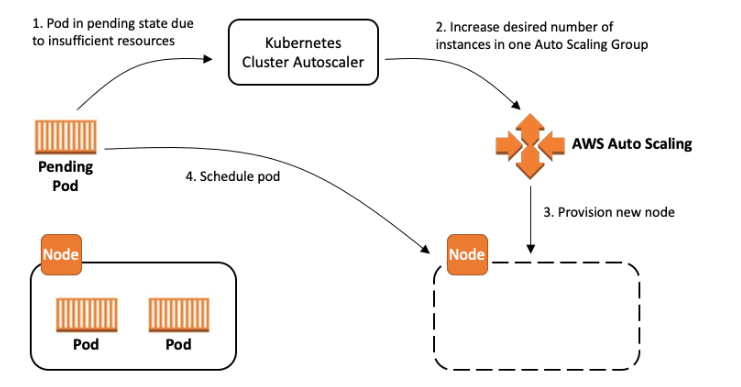
- Cluster Autoscaler เป็น Tools สำหรับ scaling node เหมือนกับ Karpenter หล่ะแต่ข้อแตกต่างคือมัน Support กับ Cloud provider เกือบทุกเจ้าเลยมั้ง ส่วนวิธีการ setup อาจจะต้องไปดูในแต่ละเจ้าเองว่าเหมือนกันไหม แต่หลักๆเราจะต้องไปเพิ่ม Permission อะไรต่างๆให้ service ตัวนี้ก่อน ซึ่งในบทความนี้เราจะมา setup kubernetes cluster autoscaler กันผ่าน Helm กับ Terraform บน AWS EKS
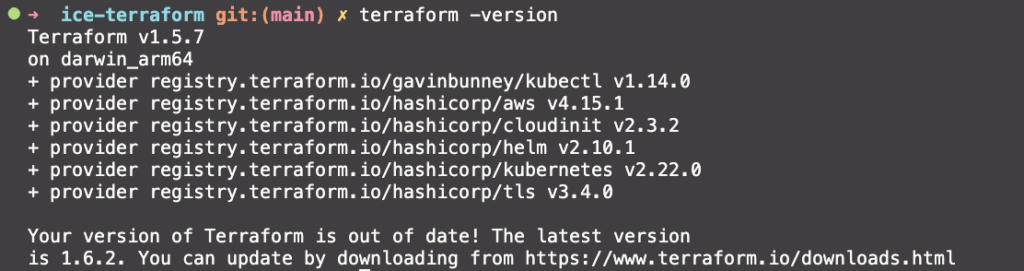
ก่อนเริ่มกันมาเช็ค Tools ที่ต้องใช้กันก่อน
- Terraform ซึ่งผมจะใช้เป็น version 1.5.7
มาเริ่มกันดีกว่า
เริ่มจากมา Clone project ของผมที่อยู่ใน Github ก่อน ซึ่งจะอยู่ในนี้
terraform-eks-cluster-autoscaler
Terraform deploy K8s Cluster-autoscaler with Helm
https://github.com/toygame/terraform-eks-cluster-autoscaler.git
อธิบาย Terraform คร่าวๆก่อน
จาก Repo ข้างบนนี้หลักๆเลยเราจะทำการ Provision 3 module ใหญ่ด้วยกันคือ
- VPC
- AWS EKS
- Cluster autoscaler with Helm
ส่วน module/resource อื่นๆจะเป็นแค่ส่วน Support การทำ Autoscaling เฉยๆ
Module VPC
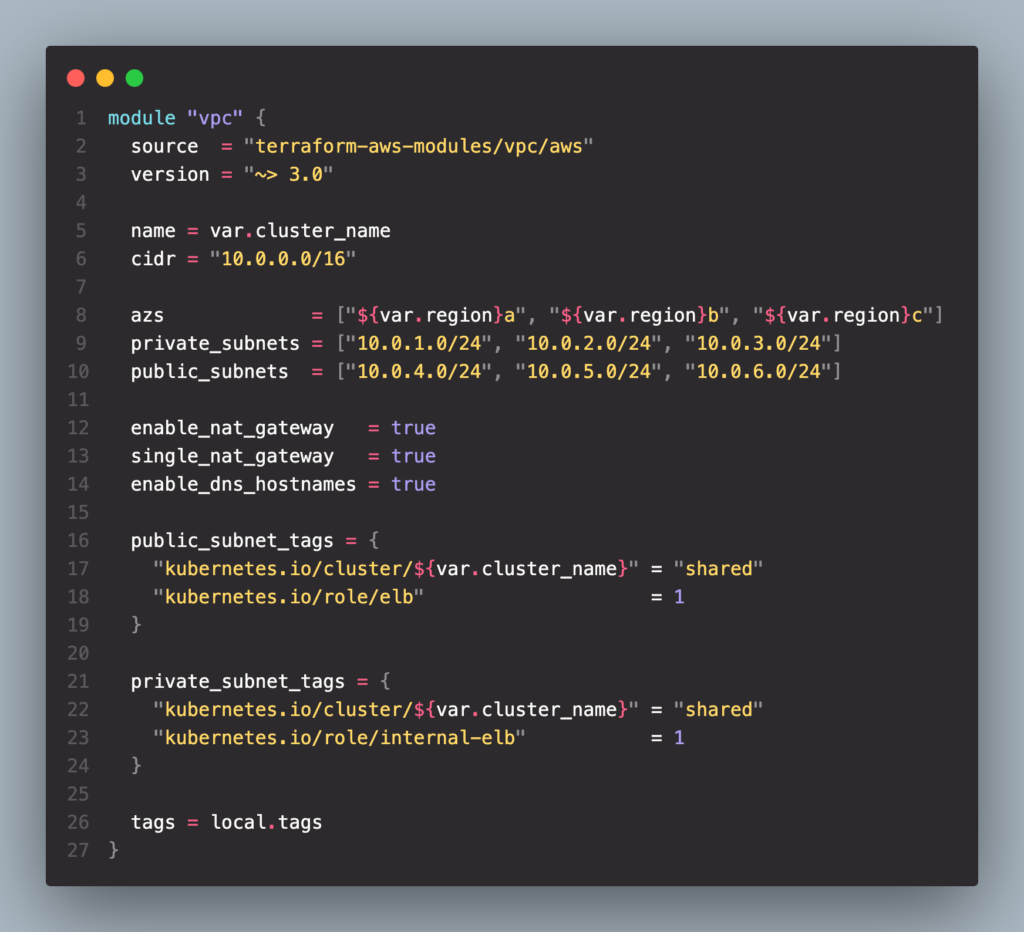
จาก code block ด้านบนจะเป็นการ provision VPC ที่เราต้องการจะให้ EKS cluster เราไป provision ในนั้นซึ่งจะมีการสร้าง Public/Private subnet ต่างๆและพวก Nat gateway กับ Internet gateway ต่างๆด้วยกัน อ่ออีกเรื่องจะเป็น Available zone[az] เพื่อทำ HA โดยที่ EKS กำหนดไว้ว่า az จะต้องมีตั้งแต่ 2 az ขึ้นไป
Module EKS
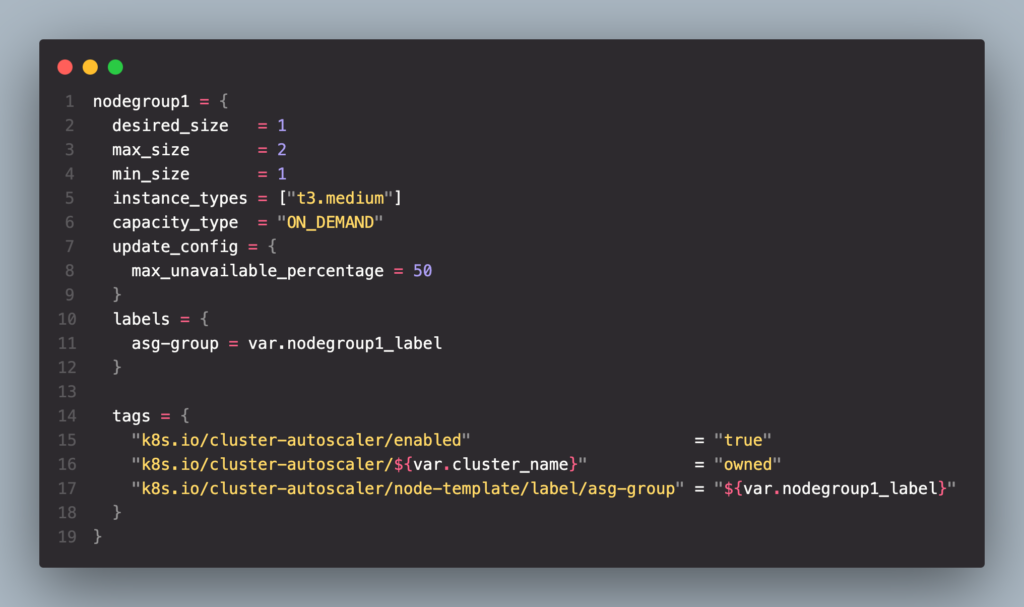
หลังจากนั้นเมื่อมายัง Module EKS เบื้องต้นผมจะกำหนดให้มันสร้าง Node group ขึ้นมา 2 Node group ซึ่ง Group แรกจะเพิ่ม Label เป็น “asg-group”: “group1” และเพิ่ม Tag เพื่อบอกให้ cluster-autoscaler มา Scale node group นี้
- Node group 1
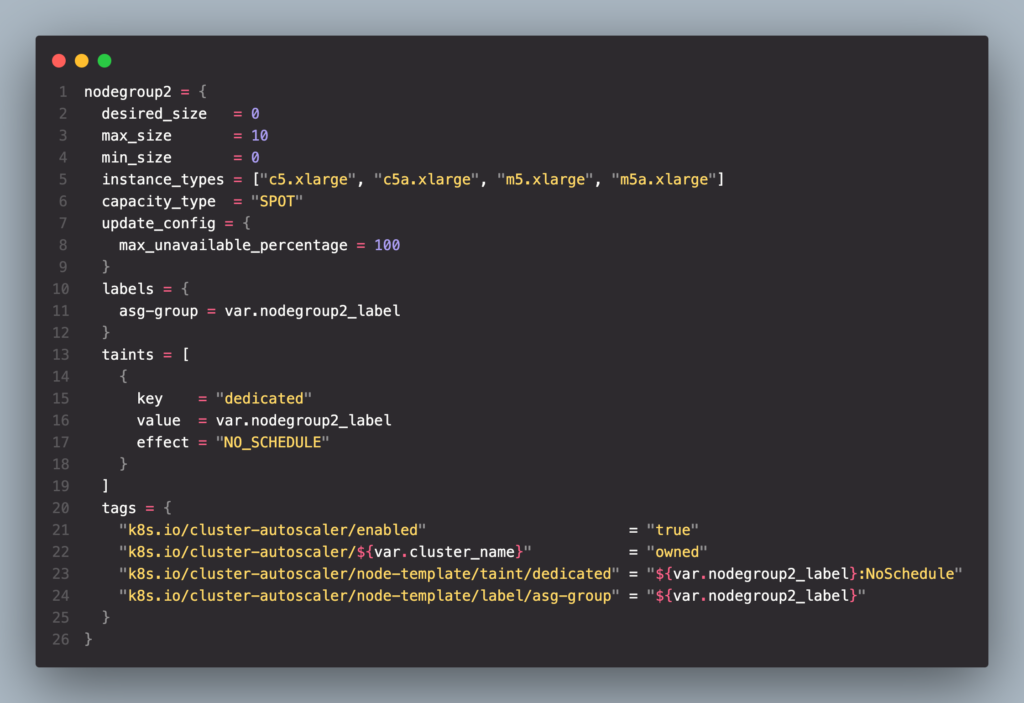
- Node group 2
ส่วน Node group ที่ 2 นั้นจะเพิ่มส่วน taints/tolerance ขึ้นมาเผื่อในกรณีที่เราอยากจะให้ Node ที่รันใน Node group นี้รัน Hardware ชนิดพิเศษเช่น ต้องการใช้ GPU เพื่อรัน Model อะไรบลาๆซึ่ง cost ของ Node ประเภทนี้จะมีราคาสูงกว่าปกติมาก
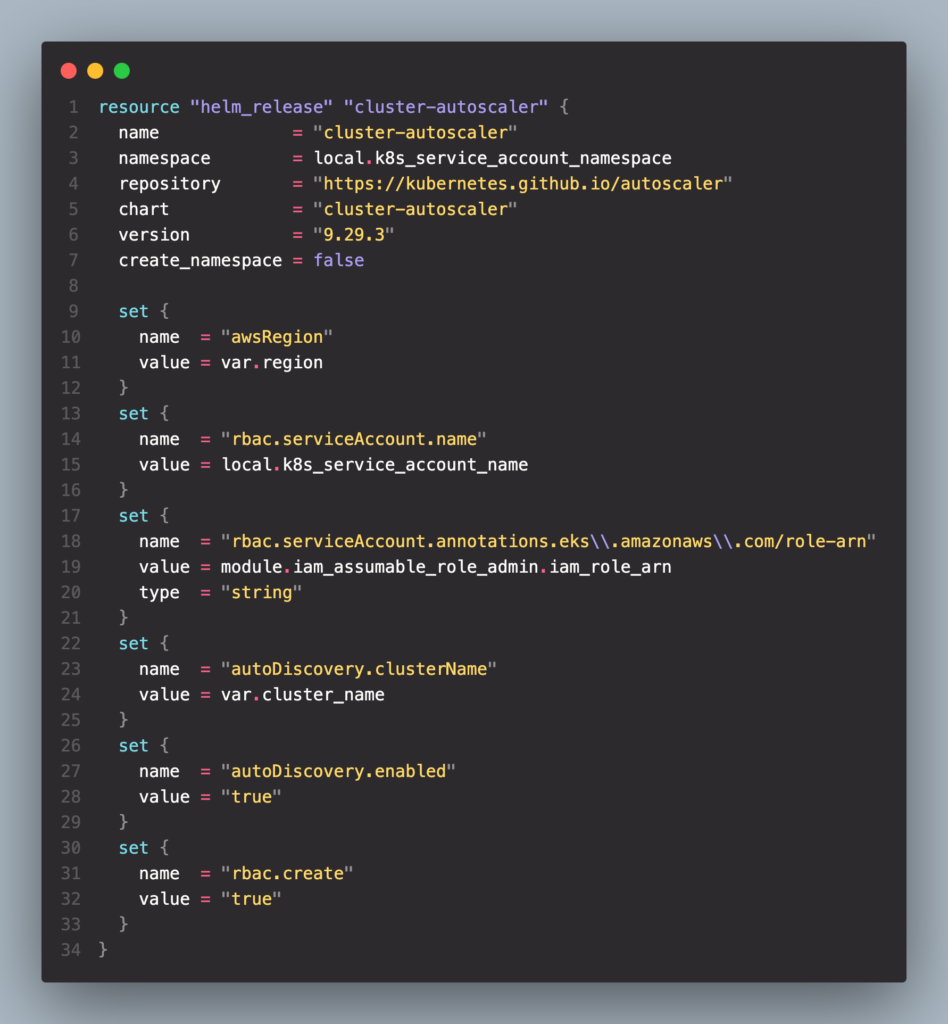
Helm Cluster autoscaler
ทำการ Release helm chart โดยที่เราจะต้องกำหนด
- awsRegion: กำหนด Region ที่ใช้งานอยู่
- rbac.serviceAccount.name: ชื่อ Service account
- rbac.serviceAccount.annotations.eks.amazonaws.com/role-arn: Service account Role-Arn
- autoDiscovery.clusterName: กำหนดชื่อ EKS cluster
- autoDiscovery.enabled: Enable auto-discovory
- rbac.create: เพื่อสร้าง RBAC resources
Running Terraform
เริ่มทำการ Init terraform เพื่อให้ Terraform package ของเราทำการ list dependencies ต่างๆโดยใช้คำสั่ง
ในกรณีที่เราต้องการ parse variable ลงไปด้วยเราจะต้องใช้คำสั่ง “-var-file=ชื่อไฟล์.tfvars”
terraform init
เช็คความถูกต้องของ Terraform รวมทั้ง preview resource ที่จะทำการ deploy
terraform plan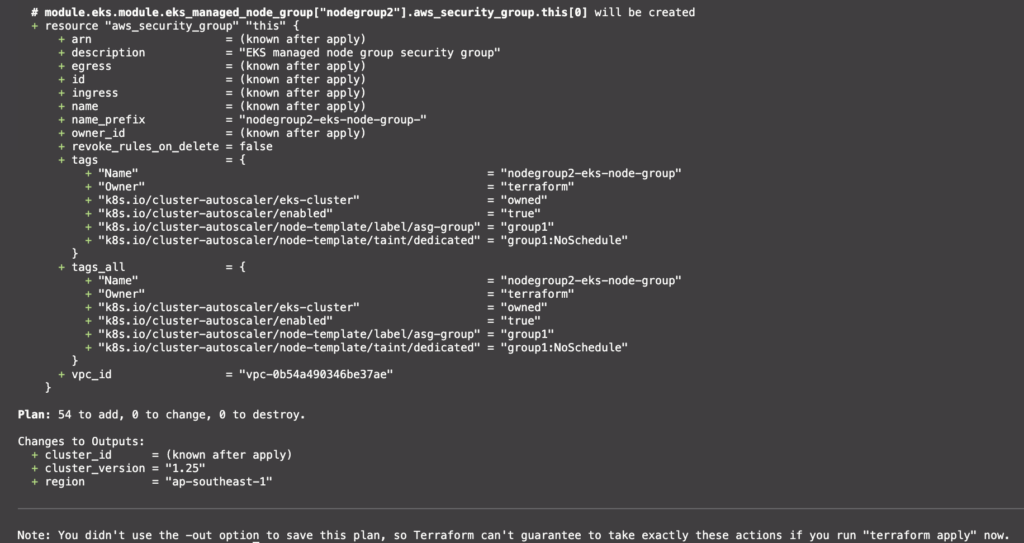
เมื่อเช็คดู Resource ที่จะ deploy ผ่าน terraform plan แล้วไม่มีปัญหาอะไรก็ทำการ Deploy จริงๆโลด
terraform applyรอจนกว่าจะ deploy เสร็จสิ้นอาจจะใช้เวลานานนิดนึงนะครับ
ทดสอบ Deploy Pod ลงไปใน Cluster ดูสิ่
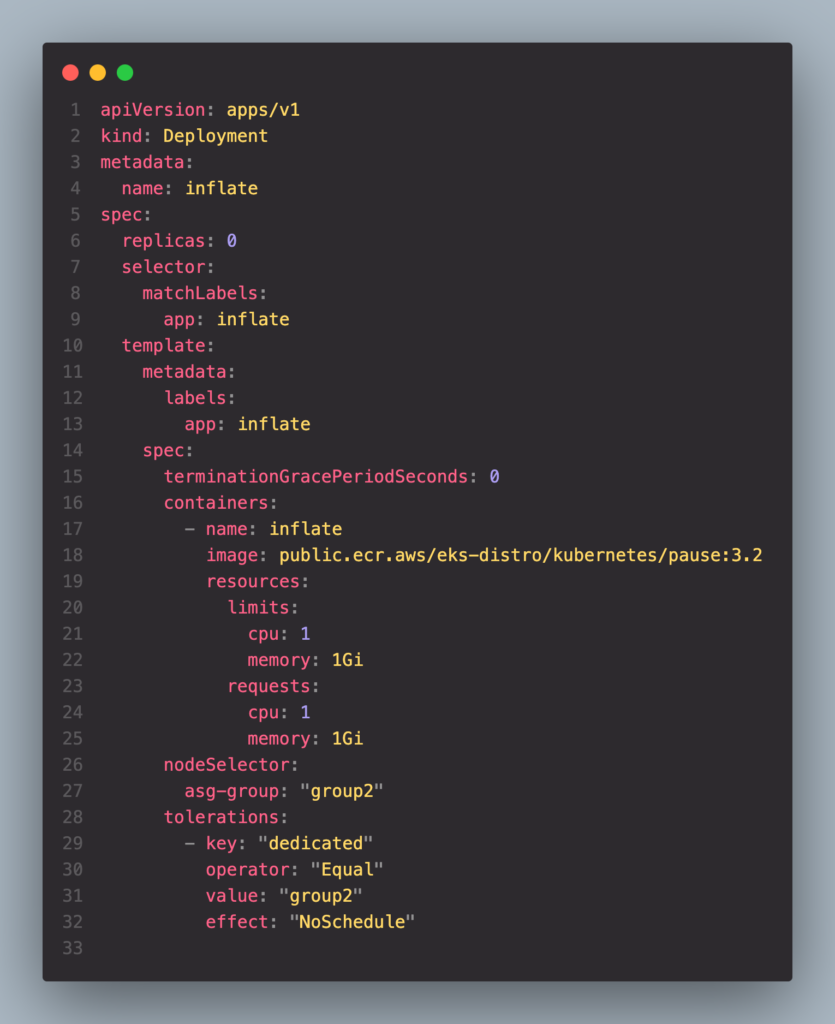
ลอง Deploy deployment ดูสิ่ โดยที่ผมจะกำหนด replicas=0 ก่อน ส่วน Resource ที่ Pod แต่ละตัวใช้จะเป็น CPU: 1CPU/Memory: 1Gi
kubectl apply -f k8s/deployment.yamlเสร็จแล้วก็ลอง Scale Pod ขึ้นมาเป็น 5 Pod
kubectl scale deployment inflate --replicas 5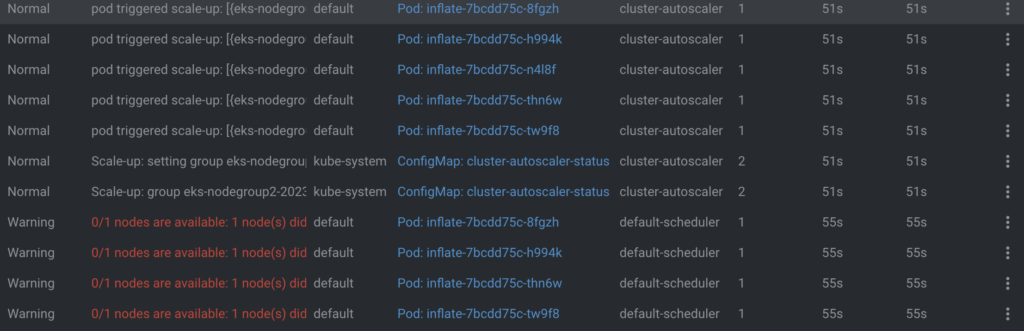
หลังจากที่เราทำการ scale pod ขึ้นมา 5 pod นั้น จากรูป cluster มันจะงอแงว่า ไม่มี Node ตัวไหนที่ว่างจะ schdule pod ตัวนี้แล้วนะ จากนั้น cluster-autoscaler จะทำการ trigger node ขึ้นมาใหม่เพื่อให้มันสร้าง Node เพื่อให้รองรับกับจำนวน Pod ที่เพิ่มเข้ามาใหม่นั้นเอง โดยที่การ scale จะอ้างอิงกับ Autoscaling group ที่เราสร้างไว้ใน Nodegroup ตอนที่ deploy EKS ขึ้นมา
ผลลัพธ์ก็จะได้ Pod ขึ้นมาใหม่ 5 Pod พร้อมกับ Node ขึ้นมาใหม่อีก 2 Node (ip-10.0.1.176, ip-10.0.2.151) เช่นกัน
Node

Pod

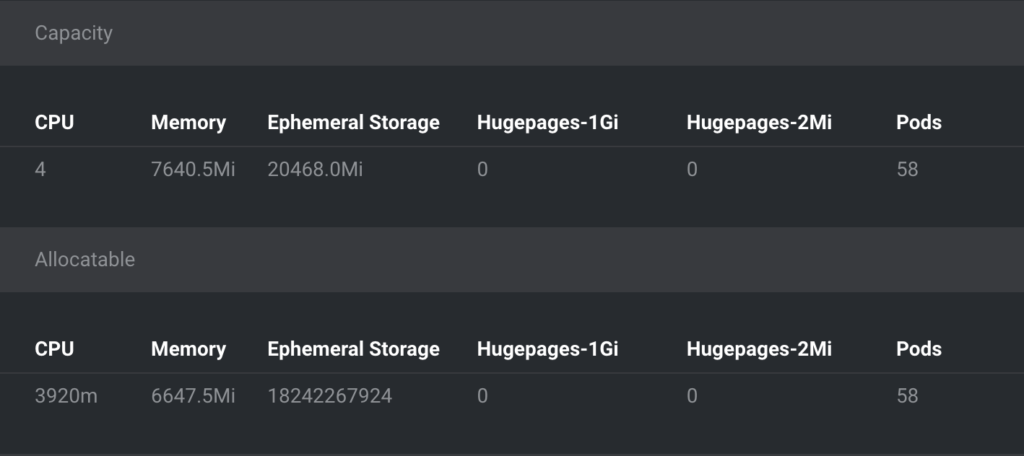
ทำไมต้องเป็น 2 Node เพราะว่า Resource ของ EC2 instance type ที่เราใช้แต่ละตัวจะถูกกำหนดไว้ที่ CPU=3.9 CPU, Memory=6.6GB ซึ่งตัว Pod ของเรามันทำการจอง resource ไว้ที่ 1 CPU/Memory 1 Gi ก็ถ้าหารกันตรงๆเลยก็จะใช้ Node ประมาณ 2 Node นั้นเอง
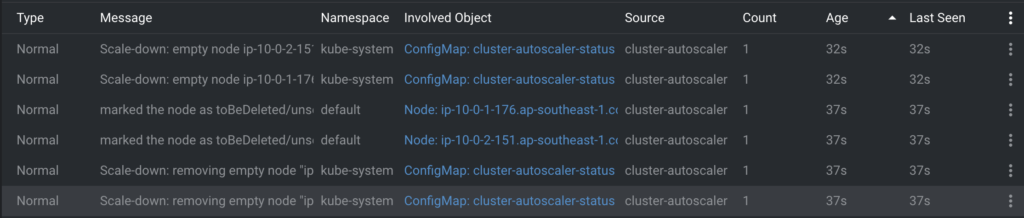
จากนั้นลองทำการ Scale down Pod ลงมาเป็น 0 replica ซึ่งในขั้นตอนนี้เราจะทำให้ Node ที่มันเพิ่ง Scale up มาเมื่อกี้ unregister ออกจาก Cluster ของเรา
kubectl scale deployment inflate --replicas 0จากนั้นรอประมาณ 10 นาที (Default value) เพื่อให้ Cluster เรา unregister worker node ออกไปตามรูปข้างล่างนี้
หลังจากที่ Deploy แล้วทดสอบทุกอย่างเสร็จแล้วอย่าลืม destroy resource ที่เรา provision ผ่าน Terraform ทิ้งด้วยนะครับ
terraform destroyเย้ จบแล้วสำหรับการทำ Cluster autoscaler แล้วเป็นยังไงบ้างครับ หวังว่าท่านผู้อ่านน่าจะได้ประโยชน์จากบทความนี้นะครับ หากมีข้อสงสัยเพิ่มเติมหรือต้องการแนะนำการใช้งานสามารถติดต่อมาได้เลยนะครับ สำหรับวันนี้ขอบคุณและสวัสดีครับ 😁